More ingredients for machine learning with neural networks
Activation functions
We have already seen rectified linear unit (relu), sigmoid, and softmax activation functions, but there are more common choices.
the hyperbolic tangent (tanh) function is very similar to the sigmoid, but maps to \([-1, 1]\) instead of \([0,1]\).
the scaled exponential linear unit (sel) avoids the large jump in derivative of the relu activation function, by attaching an exponential
An important consideration, especially for hidden layers, is that it should be avoided that the optimisation can end up in a region where the gradients are too small, or too large; it should especially not be in such a region with the typical values from the weight initialization. This happens very easily when stacking several sigmoid layers: if the weights in any layer end up in the nearly flat region, it is quite hard to get back out of there and to find the minimum. With relu hidden layers this is much less of a problem, which is one of the reasons why they are some common in deep learning.
On the other hand, there should be enough non-linearity in the network to be able to adapt to the structure in the training sample.
Preprocessing and feature engineering
As can quickly be seen in the Tensorflow playground, a deep neural network may be able to learn any structure in the input data, but some extra input features based on other knowledge of the data can make a huge difference.
In addition, neural networks are rather sensitive to the typical numerical values of inputs, so making sure that they are of order one is usually a good idea (e.g. by shifting or rescaling them by a constant factor), this is called preprocessing.
Architecture examples
Convolutional neural networks
Convolutional neural networks are often used for image recognition tasks. They use an interesting form of weight sharing: a convolutional layer applies a function on the values of a group of adjacent pixels (e.g. 2x2, 3x3, or larger), and does that every such group in the input (with the same function). They are typically followed by pooling layers that take the maximum or average of these outputs over the image, which makes that they recognize local features independently of where those are in the image (e.g. objects in a picture).

Recurrent neural networks
Recurrent neural networks do not take a fixed number of inputs, but a sequence of (fixed-size) inputs, and are often used in applications like speech or handwriting recognition. They typically have one network unit that takes one input at a time, and passes some of its outputs as inputs along with the next input element, thus creating internal memory of the network. One of the main challenges is to do so without the gradients getting too small or too big, because they pass through the network as many times as there are elements in the input sequence. A well-known solution to this is the LSTM cell.

Graph neural networks are a more general class of neural networks that take structured data of variable size, and with more complex relations than being elements of a list, as input.
Generative adversarial networks
Generative adversarial networks solve a slightly different problem: how to generate data that looks like the input. To do so, two networks are trained, a generator that takes random number as input, and produes an output (e.g. image) from them, and a discriminator network that is trained to distinguish between the real training sample and the generated one. They are trained with opposite loss functions: the generator tries to make examples that the discriminator cannot tell apart from the real ones, while the discriminator tries to distinguish them. Both are trained together, after some training step of the generator, the discriminator is updated; training can be tricky, it is important that the discriminator always stays close to optimal, such that it gives the right feedback to the generator.
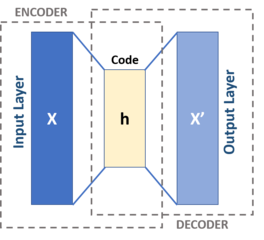
An example of unsupervised learning: autoencoders
Autoencoders can be used to learn a lower-dimensional representation of the data, or perform (lossy) compression. They consist of a neural network that is mirrored around a hidden layer with fewer nodes than the input, and are trained for the output nodes to approximate the input nodes as closely as possible.
Diagnostics
A big advantage of modern machine learning frameworks like Tensorflow is that,
in addition to making training and inference efficienty, they provide easy to
all internal values, because everything is (or looks like) a simple python
object.
Standard graphical tools like TensorBoard are very useful, but if something
specific is needed, it can often also be done with a few lines of code; the
Model.fit function for instance allows for callbacks, functions that are
called during training.